How to use the Duplicated Genes Database
Summary
1. Browse genomes for duplicated genes
In this page, you can choose to browse the list of the duplicated genes by species, by chromosome or within a specific location (you can use the "restrict to specific chromosomal region" toggle link for this purpose). Then, you can choose the output format of the results:
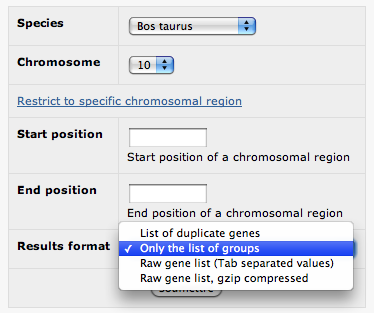
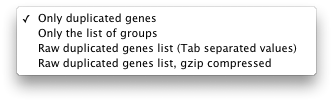
- List of duplicated genes: returns a table with all the duplicated genes, their groups and chromosomal locations (warning: page loading can be long!)
- Only the list of groups: returns a table with only the group IDs and their chromosomal locations.
- Raw gene list (TSV), compressed or not: returns a downloadable file (.tsv or .gz) with the raw data (genes lists, with groups ID and chromosomal locations)
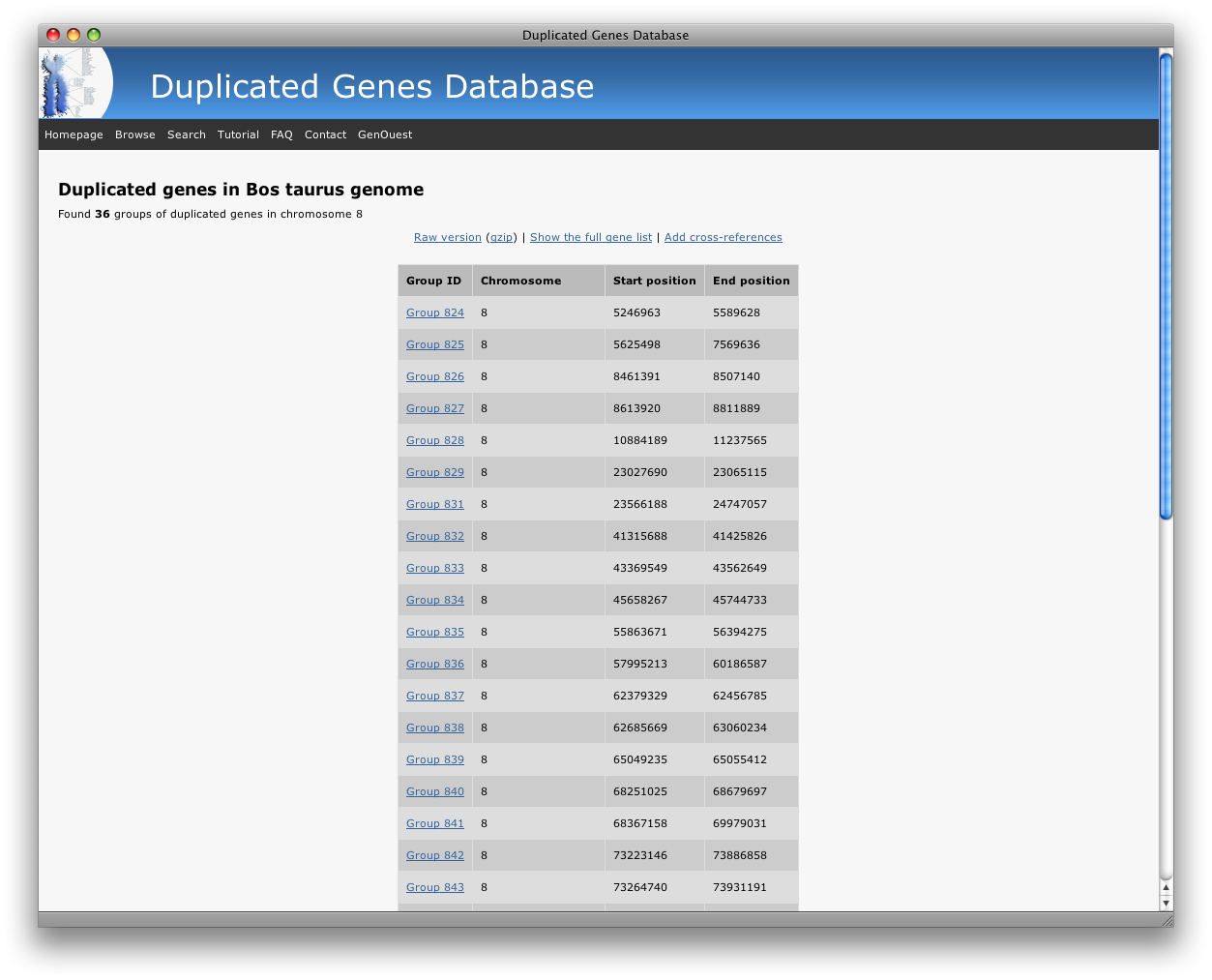
Here are some examples of the different output styles:
- Only the list of groups:
- The list of duplicated genes:
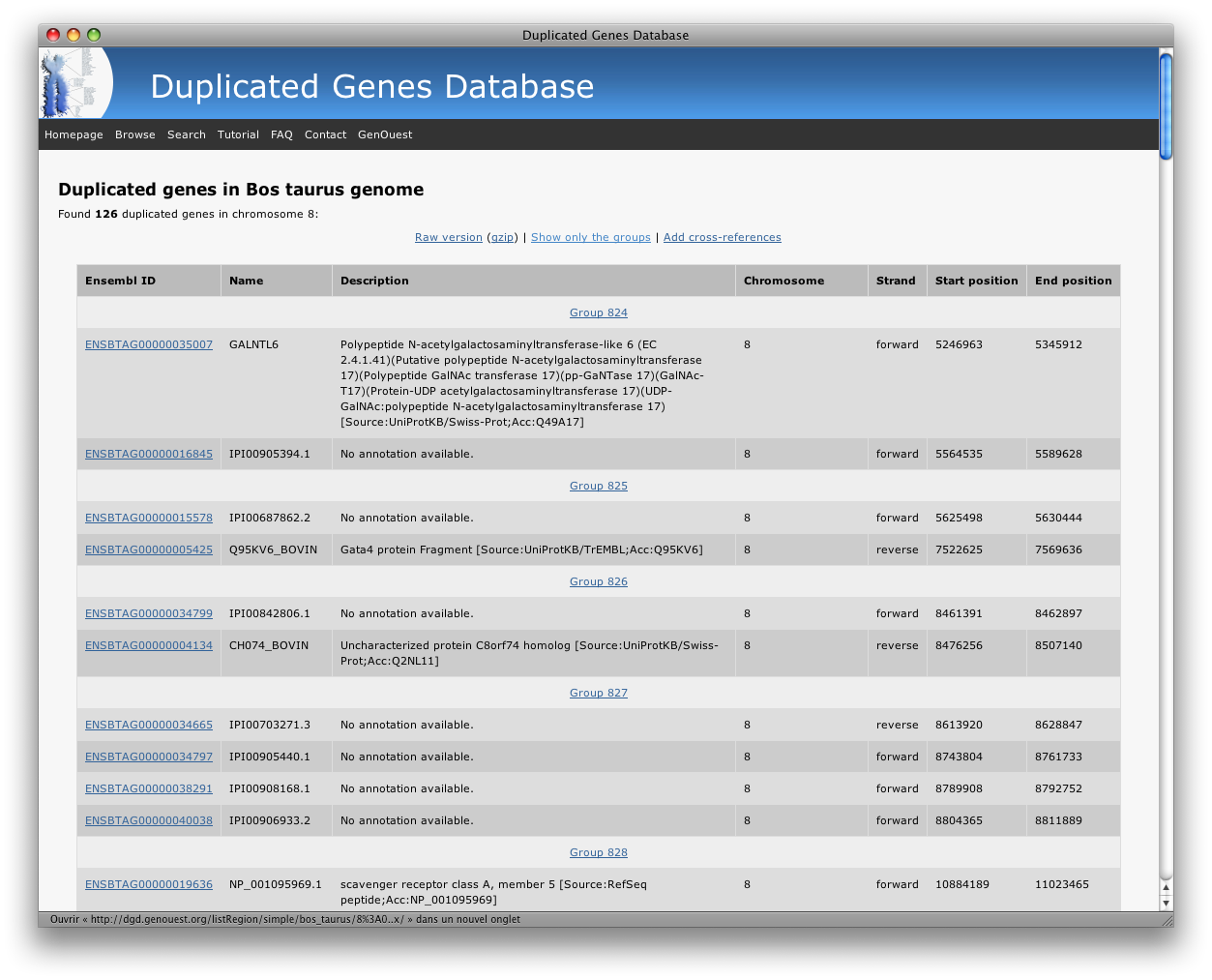
In both cases, you can always download the RAW results (TSV, compressed or not) using the 'Raw version' link at the top of the page.
You can also add cross-references to the displayed data:
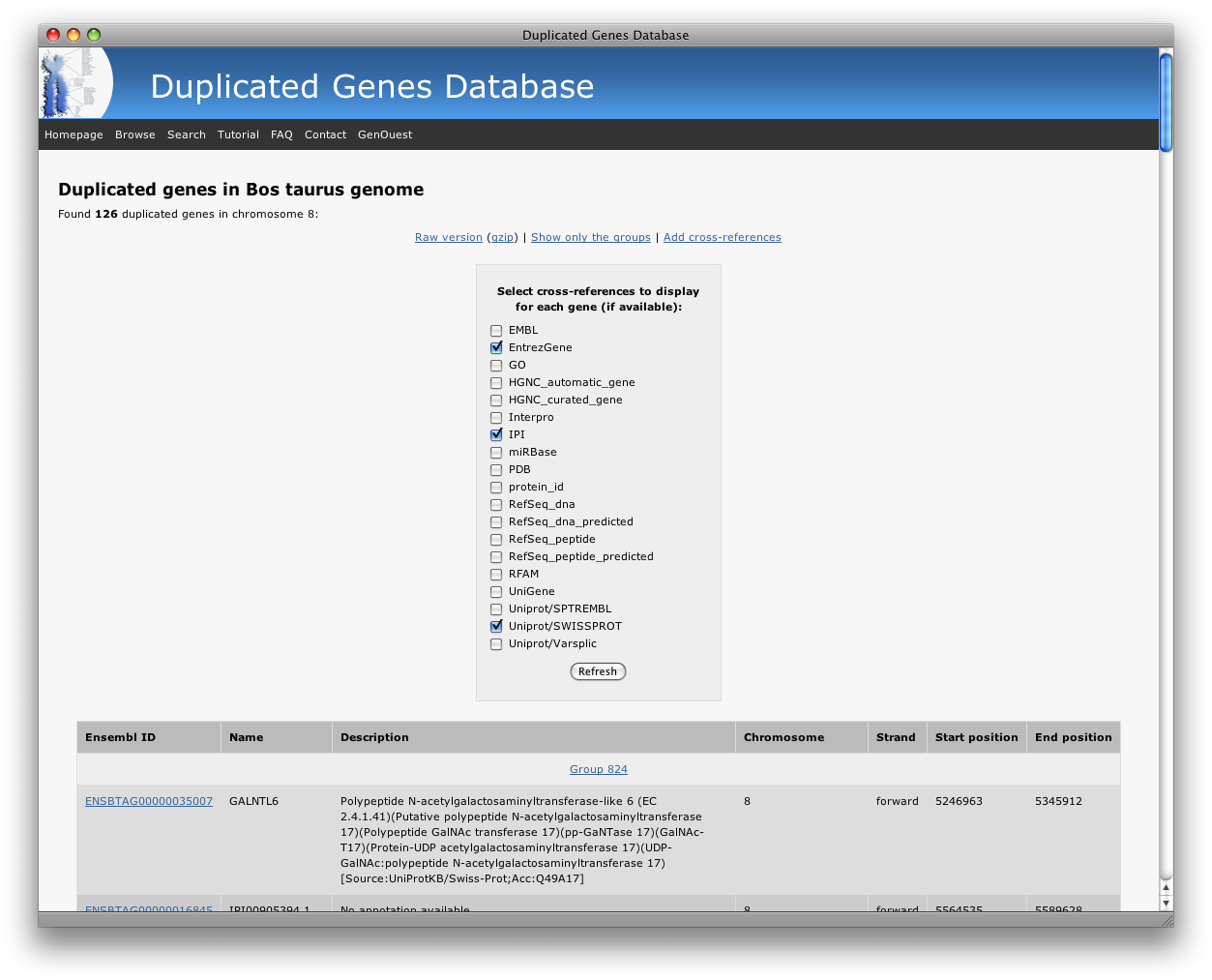
Then, click refresh and your gene list will be updated with the selected cross-references associated to each gene:
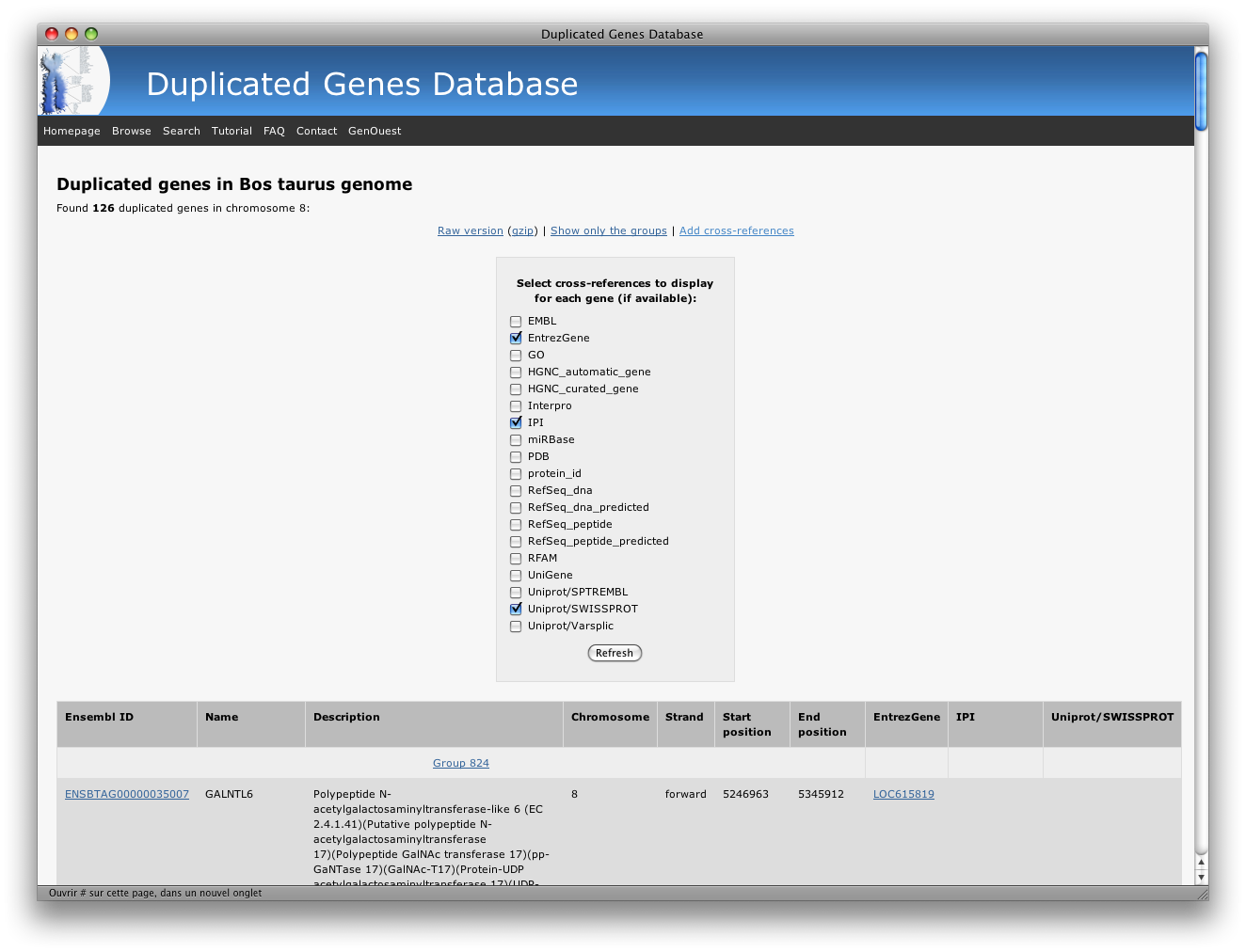
At this point, you can choose to add more xref, delete some of them or just hide the xref panel by re-clicking on the « add cross-references » link:
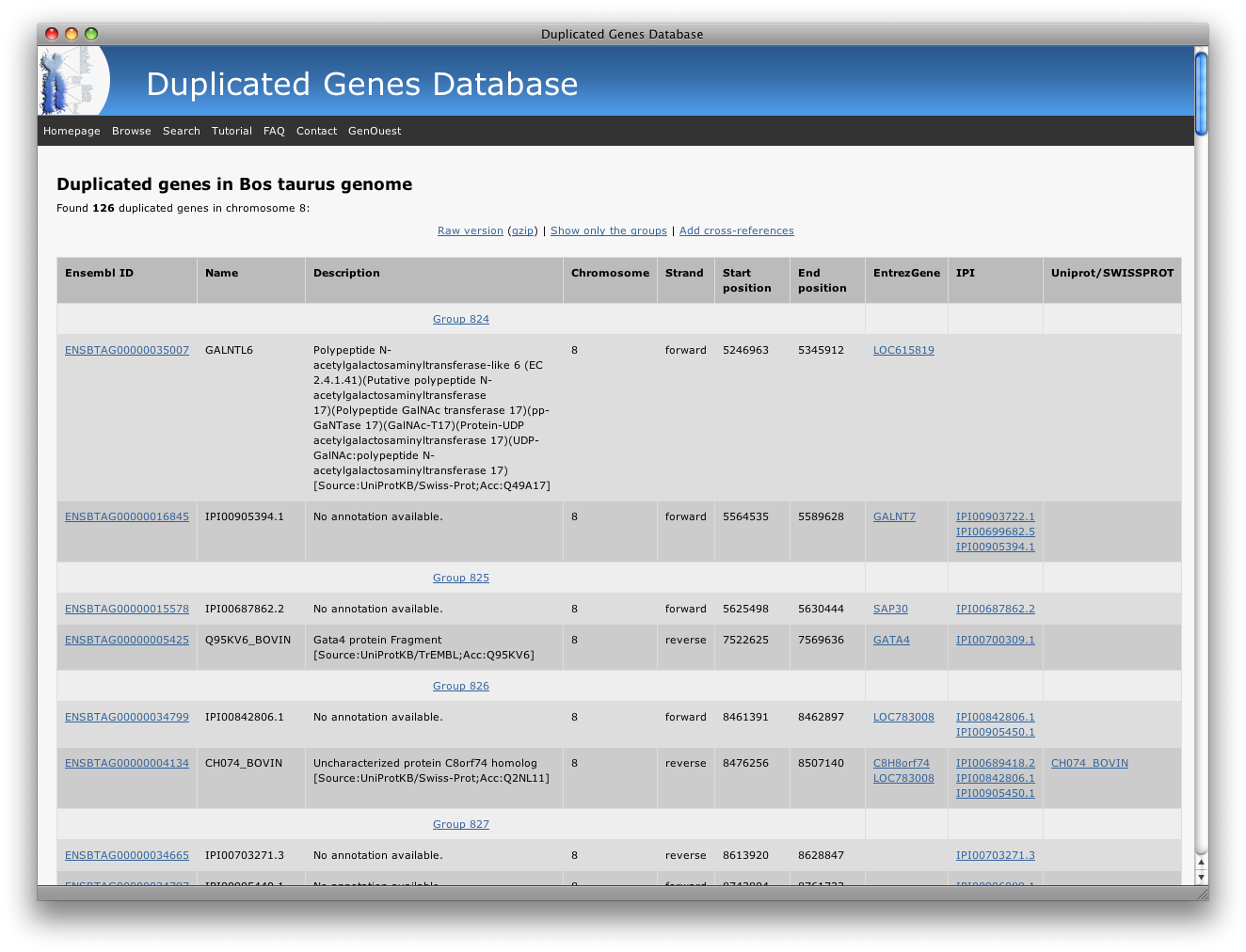
The raw version will automatically include the chosen cross-references in exported data.
Note: the available cross-references are depending on the selected species. Indeed, the databases are different depending on the species. You should also note that, due to extreme diversity of the available species-specific cross-references, adding cross-references to a "multiple species browse" is not possible at present time (maybe in the future?)
2. Search for duplicated genes
You can search for duplicated genes using either database identifiers (Ensembl, Uniprot, GenBank, ...), chromosomal regions (e.g. X:10..10000 to search within region 10 to 10000 in chromosome X), or keywords. You can copy/paste/type several IDs or keywords in the input box (one query per line). But, you can also upload a text file with the IDs or keywords (one query per line). You can also select the species in which the queries will be carried out. Please note that it is also possible to perform a wide-species search (note: when using IDs, you don’t need to specify the species as many of them (like Ensembl ID) are species-specific).
Search by ID

The previous search will show you the following results:
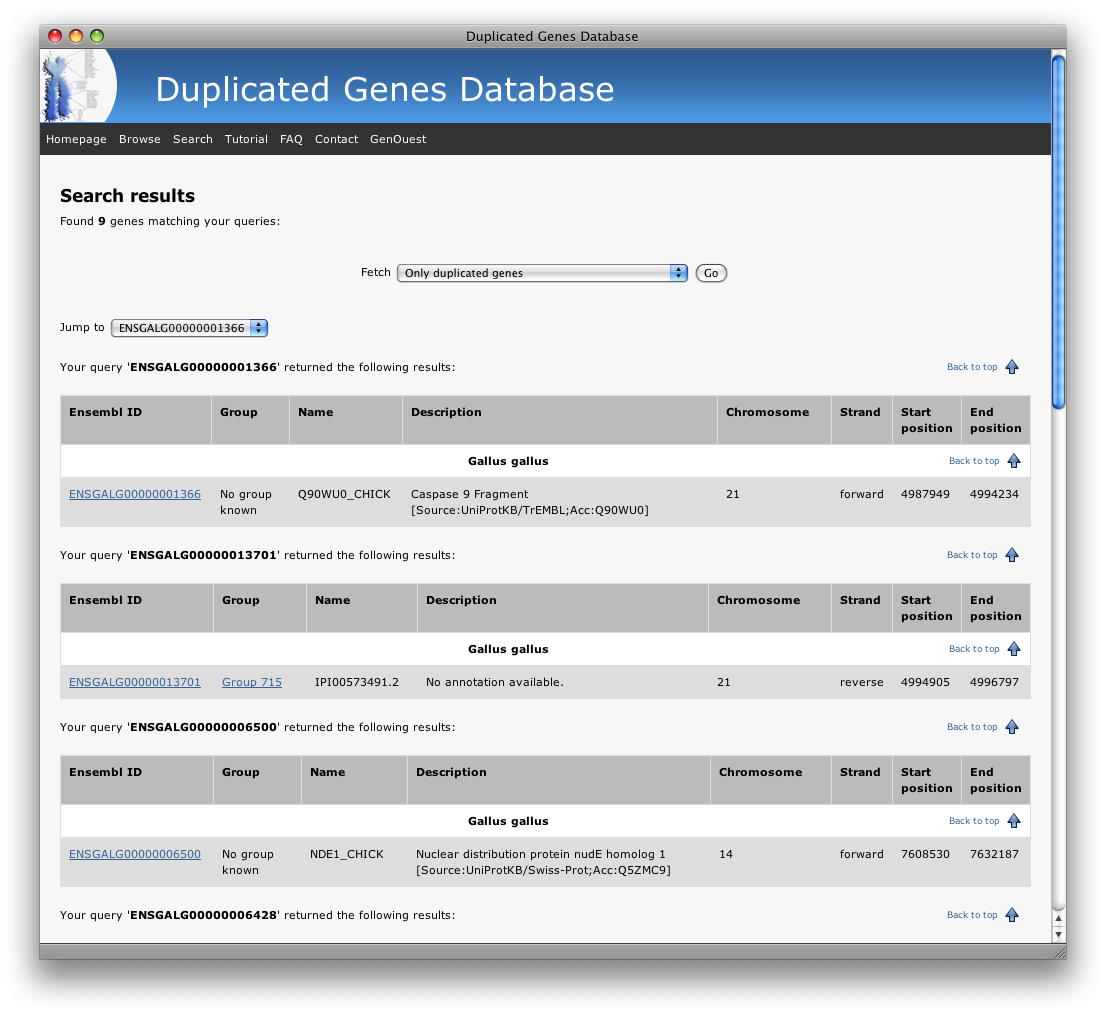
Then, you can filter your results to remove the genes that do not belong to any group of duplicated genes:
You will obtain the following results for the list of only duplicated genes:

On the left of your screen, a jumpbox allows you to easily navigate between the searched IDs:
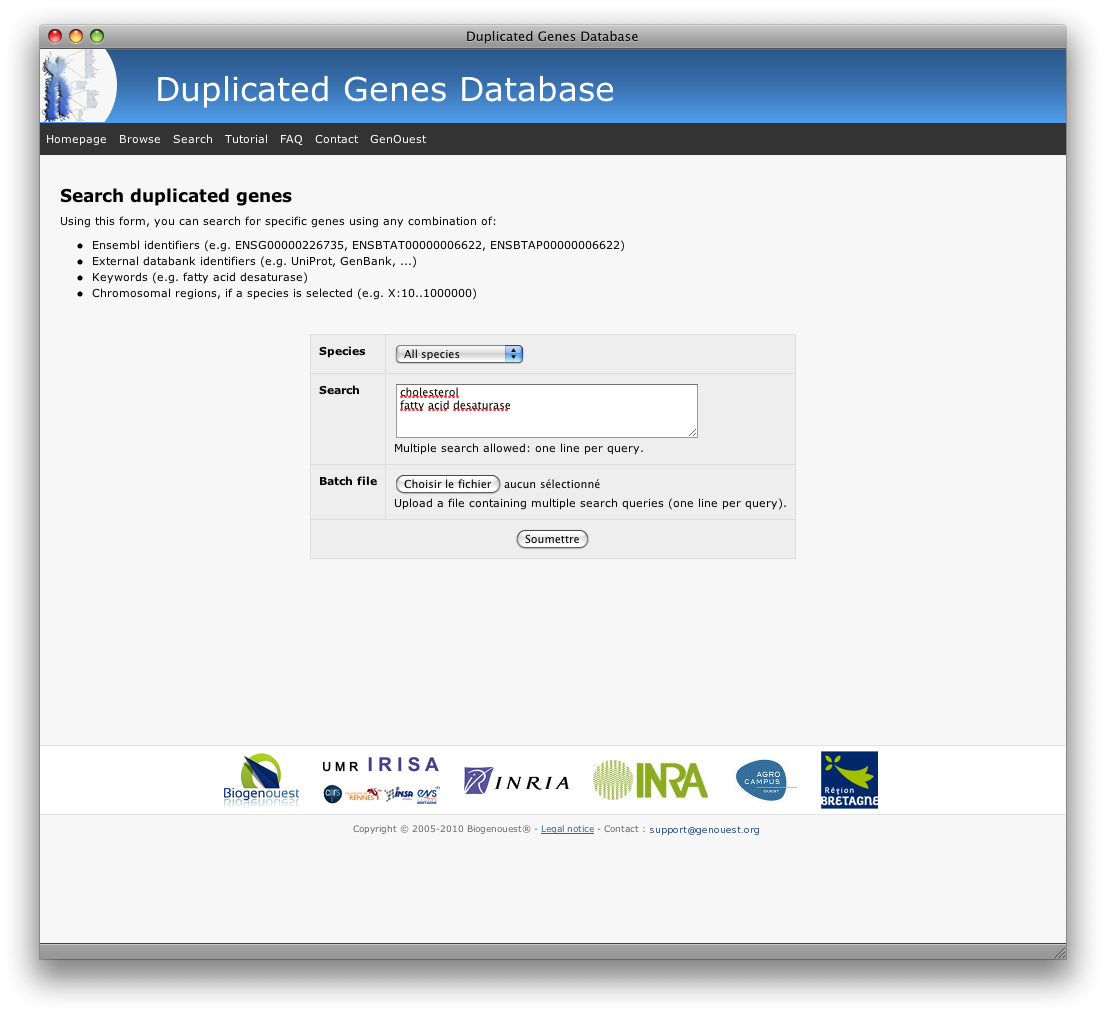
Search by keywords
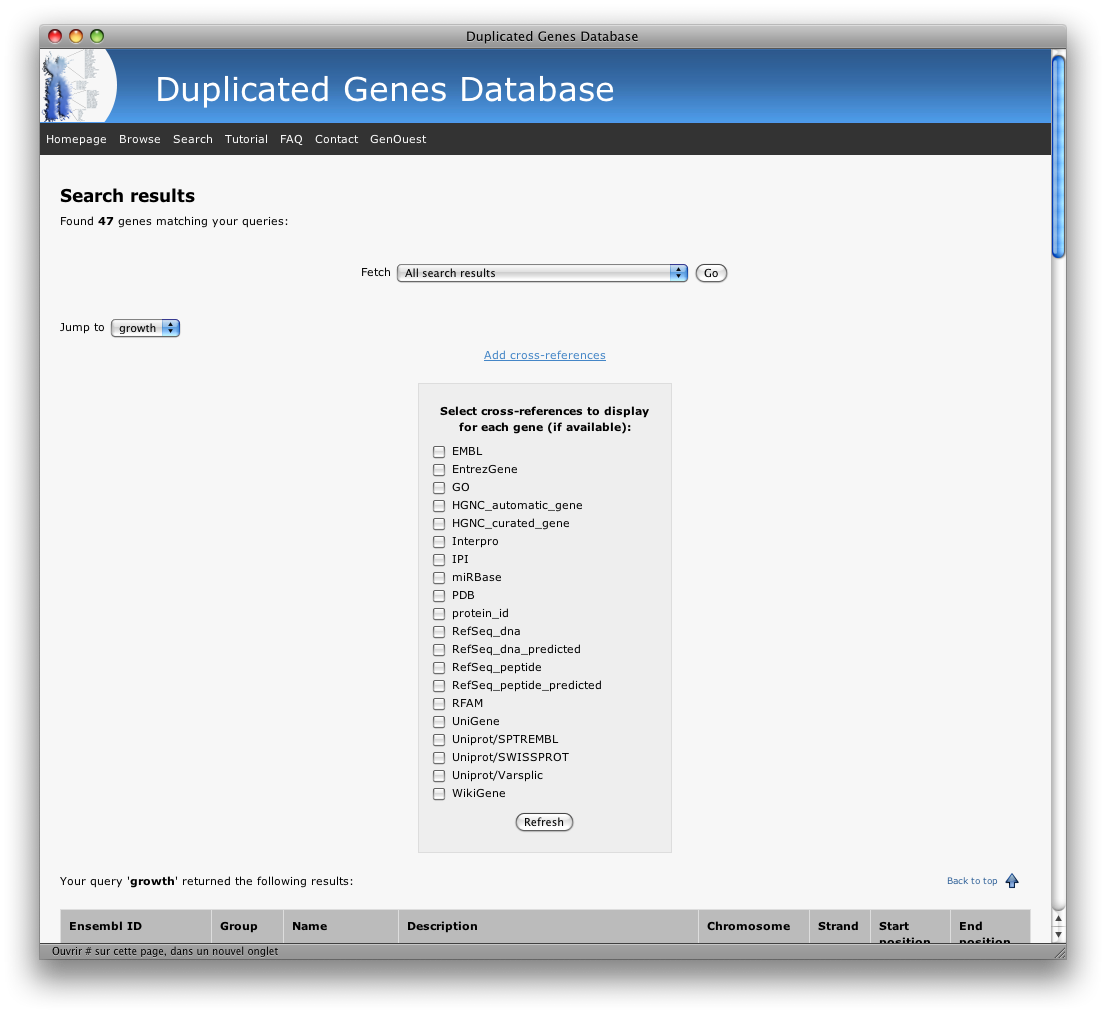
Similar to the search with ID, you can also search for duplicated genes using keywords (one or several terms, either by typing them in the input box or by uploading a text file to the server).
You will get the following results:
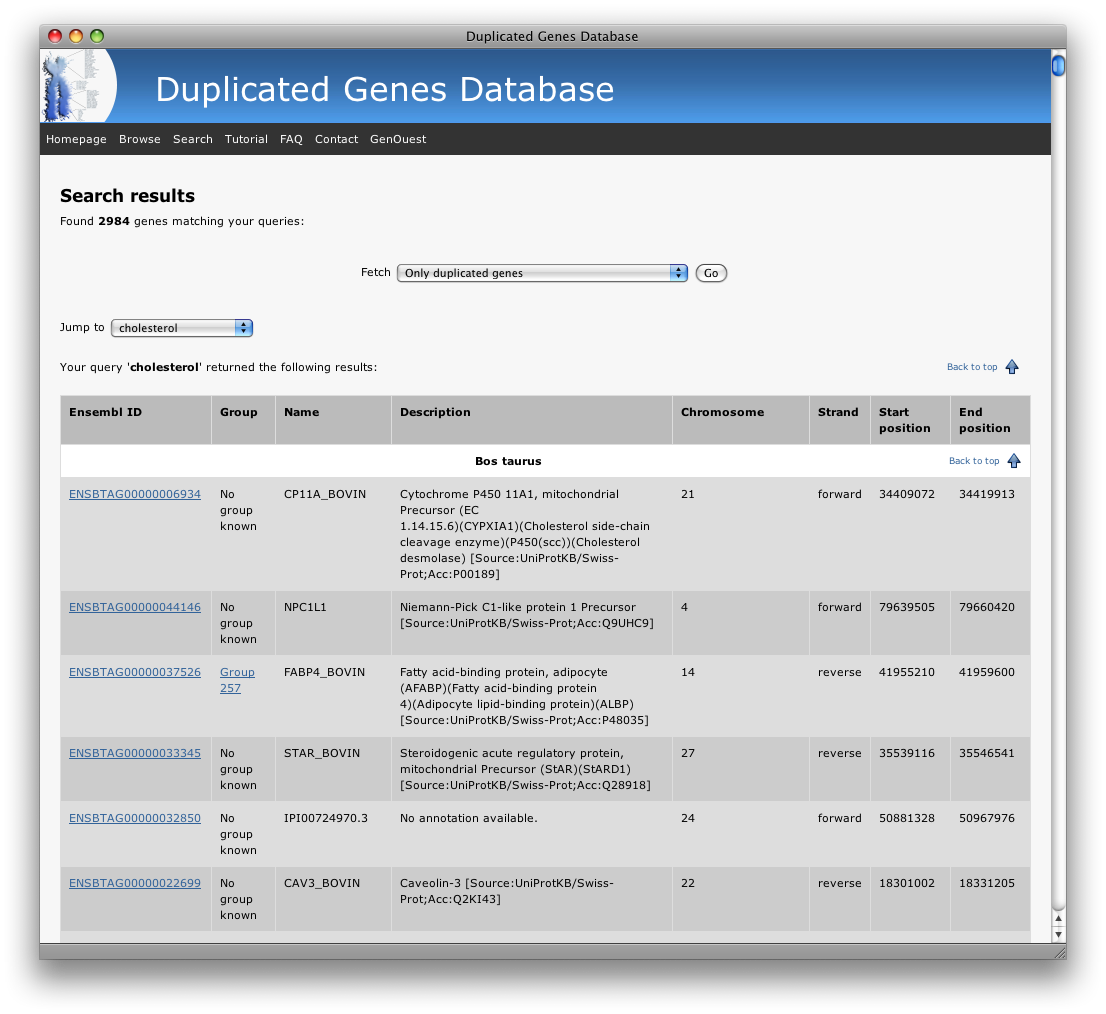
Again, you can filter displayed results by selecting in the "fetch list" only duplicated genes or only the list of groups:
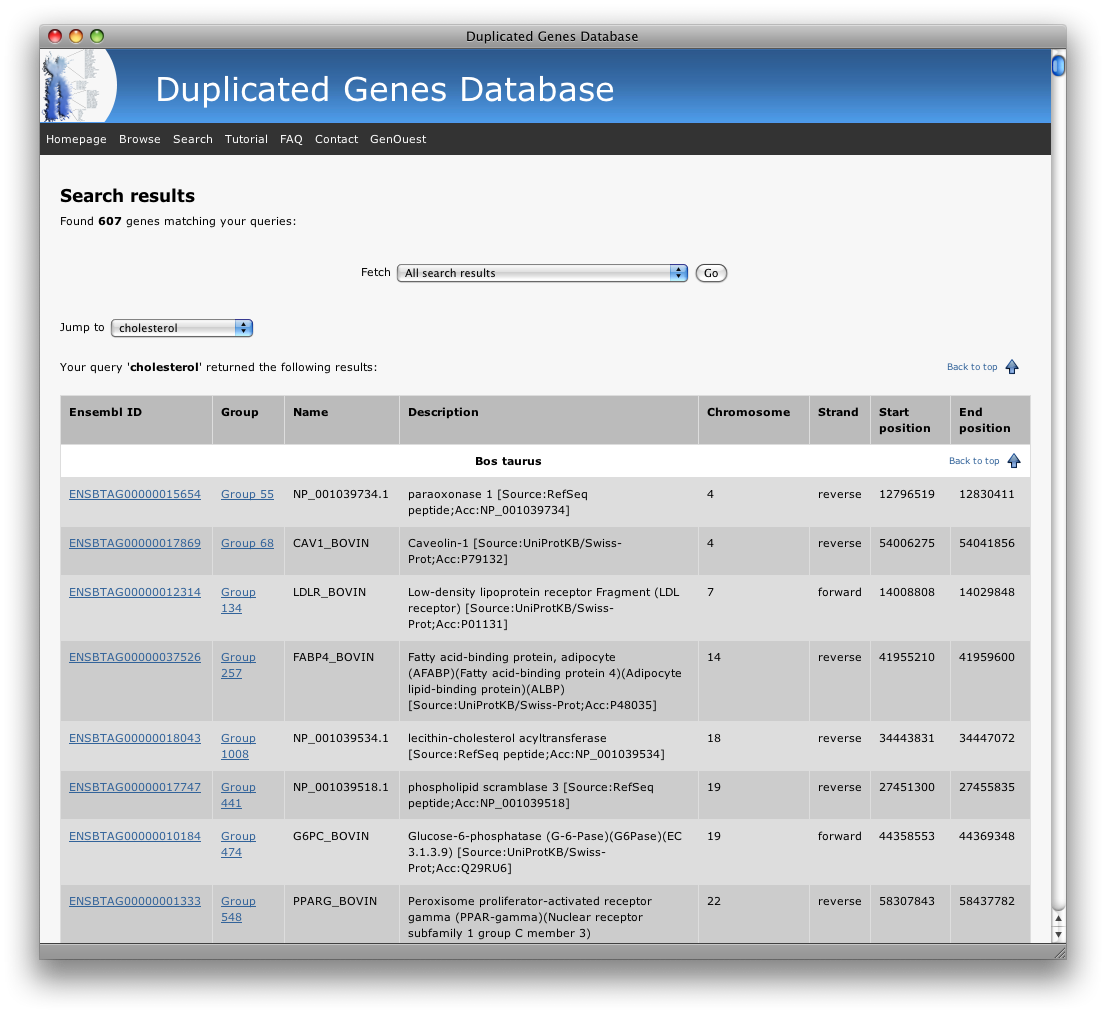
The jumpbox on the left allows to navigate between the species and the searched keywords:

If you perform a species-specific search, you will be able to add cross-references as in the browsing mode (this is not possible with mutliple species results for performance reasons):
3. DGD as a webservice
SOAP webservice
DGD is available as a webservice using the standard SOAP protocol. The WSDL file is available at this address.
A minimalistic web interface is available to test the service invocation.
This webservice can only carry out the Ensembl gene IDs as input data and cannot allow retrieving directly xrefs in output file. However, these features are available using another complementary webservice dedicated to cross-references: Xref (web interface).
The Xref service allows you to retrieve the list of available cross-references sources for a given species. You can also retrieve a list of cross-references corresponding to the Ensembl gene IDs, or to search for Ensembl genes using different cross-references (IPI or GenBank identifiers for example).
GenOuest platform is providing several other webservices, which are available here. Another source of usefull webservices is BioCatalogue.
Invoking DGD from java code
Using the webservices, you can execute DGD requests directly from your java code. WSDL2Java is the perfect tool to achieve that.
Reading the Axis2 documentation is a good idea to start using WSDL2Java, but here are the main steps (tested on linux platform but it should work on other platforms):
First download Axis2 from the project website. Uncompress the archive somewhere on your hard disk drive and define AXIS2_HOME environment variable (as the method depends on your OS platform, see the Axis2 documentation for more details).
Once Axis2 is installed, you can use the WSDL2Java script that is included in Axis2 archive:
$AXIS2_HOME/bin/wsdl2java.sh -d adb -s -uri http://webservices.genouest.org/typedservices/DGD.wsdl -p a.custom.pack.name -o /tmp/outputFolder
This command will generate some java classes that will be needed to invoke the webservice in your program.
The next step is to create a jar file for these classes:
ant jar.client
Once finished, you are ready to use this new library in your java code. Here is a simple example of an application that performs a DGD request. Do not forget to add your new jar file and axis2 libraries in your classpath.
package test.pack;
import org.apache.axis2.AxisFault;
import a.custom.pack.name.DGDStub;
import a.custom.pack.name.DGDStub.JobSubOutputType;
public class TestClient {
public static void main(String[] args) {
DGDStub stub =null;
try {
stub = new DGDStub();
} catch (AxisFault e) { e.printStackTrace(); }
DGDStub.JobInputType inType = new DGDStub.JobInputType();
inType.setSpecies("bos_taurus");
inType.setChromosome("1");
DGDStub.LaunchJobInput input = new DGDStub.LaunchJobInput();
input.setLaunchJobInput(inType);
try {
DGDStub.LaunchJobOutput output = stub.launchJob(input);
JobSubOutputType outType = output.getLaunchJobOutput();
System.out.println("Job "+outType.getJobID()+" submitted with status "+outType.getStatus().getCode()+" ("+outType.getStatus().getMessage()+")");
} catch (Exception e) { e.printStackTrace(); }
}
}
In this example, we use the operation 'launchJob' to request the duplicated genes on the chromosome 1 of the Bos taurus species. Another operation ('getOuputs') is available to retrieve the results.
Please note that you can use similar java code to perform requests upon the Xref database.
Using DGD within Taverna
Taverna is a software that permits the creation of complex workflows using multiple web-services.
An example of workflow for DGD would be to use the Xref webservice to search for all the genes matching with the 'FADS' search term and then to use the DGD webservice to extract the duplicated genes from those genes. Then, it may be interesting to retrieve the GO terms of each duplicated gene.
A ready to use workflow has been designed to perform this scenario and is available on myExperiment. You'll find many other workflow examples on myExperiment for other purposes (blast, clustalw, and many other tools).
